With the use of linear regression in R, this project intends to predict annual medical charges based on individual attributes such as age, BMI, smoking status, and region. The model aims to assist insurance companies in estimating appropriate premiums, balancing customer affordability and financial sustainability.

Details
R
R Studio
Excel .csv
Libraries
ggplot2/dplyr/readr
EDA, Correlations, Linear Regression
Overview
This project explores the intersection of healthcare analytics and statistical modeling by building a predictive model that estimates an individual's annual medical expenses using personal demographic and lifestyle information. Implemented entirely in RStudio Desktop, the project harnesses real-world data to simulate how insurance companies could forecast healthcare costs to optimize premium pricing. The focus is on using multiple linear regression to identify and quantify relationships between variables such as age, BMI, smoking status, and geographic region and how they influence annual medical charges.
The analysis showcases the full lifecycle of a data science workflow—from data acquisition and cleaning to exploratory data analysis (EDA), model training, and performance evaluation—making it an excellent representation of practical data science skills in action.
Key Features
Exploratory Data Analysis (EDA):
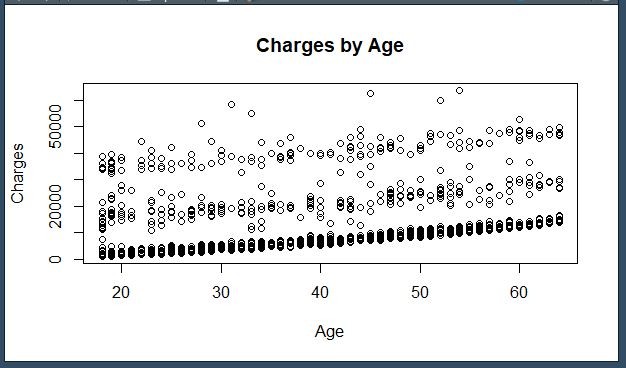
Visualized relationships between numerical features (e.g., age, BMI, number of children) and charges using scatterplots.
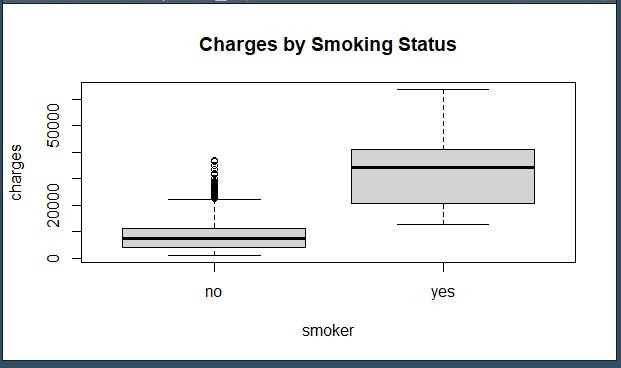
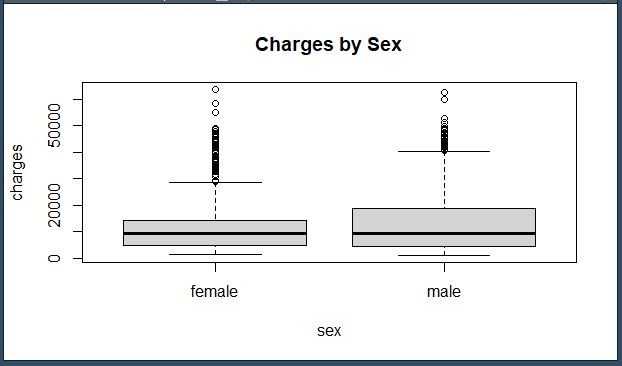
Created boxplots to examine how categorical features (e.g., sex, smoker, region) influence medical costs.
Identified non-linear trends and outlier clusters (e.g., sharp cost increases among smokers).
Model Building:
Developed a multiple linear regression model using the
lm()function in R.Handled categorical data automatically with R’s internal creation of dummy variables.
Summarized model fit using
summary()to assess R-squared and significance levels of predictors.
Model Performance:
Achieved a respectable R-squared value of ~0.75, indicating the model explains approximately 75% of the variance in annual charges.
Identified key predictors: age, BMI, number of children, and smoking status had the strongest influence on predicted cost.
Interpretability:
Used statistical significance levels (p-values) to determine impactful vs. non-impactful variables (e.g., gender was not statistically significant).
Mission
The mission of this project is to simulate a real-world insurance pricing scenario by applying statistical modeling techniques to personal health data. The goal is to understand how demographic and lifestyle variables impact healthcare costs and to build a transparent, interpretable model that helps health insurers estimate fair and data-driven premiums.
By doing so, the project seeks to demonstrate the practical application of regression analysis in the insurance and healthcare sectors, where data-driven decision-making is critical for minimizing risk, improving accessibility, and maintaining competitive pricing strategies.
It also serves as a hands-on learning tool to practice core data science competencies, from EDA to model evaluation, while offering insights into the ethical implications of predictive modeling in personal finance and healthcare.
Impact
The impact of this project spans both professional growth and practical industry relevance. From a career standpoint, it demonstrates proficiency in statistical modeling and R programming—skills that are highly valued in healthcare, insurance, and financial analytics roles. It simulates how real-world businesses, particularly health insurers, can leverage predictive analytics to improve pricing strategies, risk assessment, and cost forecasting. Furthermore, it emphasizes the importance of ethical data use and model transparency, showcasing the role data science plays not just in prediction, but in making informed, responsible decisions that affect individuals' financial and medical well-being.